
Today I Learned: Row Locking Transaction in PostgreSQL
How I did Locking in a Row for Read-Write Transactions in Postgres. - It took me 2 days to attempt to solve this, but the solution is actually very simple and elegant.

Today’s problem is a hard problem but has a silly solution. So, right now, I’m working on some stuff in Xendit, my current employer. I’m working on the refactoring of our core-payment system that will handle the payment transaction from/to each bank that we supported.
And, when I’m developing this new core service, one of the services is related to hashing and generating a payment code, let’s call it Payment Code Generator service. The payment_code needs to be random but also unique, but we won’t go into there for the details. But in short, it will require a counter to generate and that is why we need to store the counter.
So, I would tell the scenario in a simple one. Let’s say I’m building a service that will generate payment code.
In this service, I have 2 tables. Let’s say master_counter and payment_code.
The master_counter table schema.
BEGIN;
CREATE TABLE IF NOT EXISTS master_counter(
id varchar(255) NOT NULL PRIMARY KEY,
user_id VARCHAR(255) NOT NULL,
counter bigint NOT NULL,
created_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL,
deleted_at timestamptz,
CONSTRAINT master_counter_user_id_unique_idx UNIQUE (user_id)
);
COMMIT;
And the payment_code schema
BEGIN;
CREATE TABLE IF NOT EXISTS payment_code(
id varchar(255) NOT NULL PRIMARY KEY,
payment_code varchar(255) NOT NULL,
user_id varchar(255) NOT NULL,
created_at timestamptz NOT NULL,
updated_at timestamptz NOT NULL,
CONSTRAINT payment_code_unique_idx UNIQUE(payment_code, user_id)
);
COMMIT;
So, in the master_counter, I have a counter column that will always be increased based on received requests. If we draw into a diagram, the flow will more look like this.
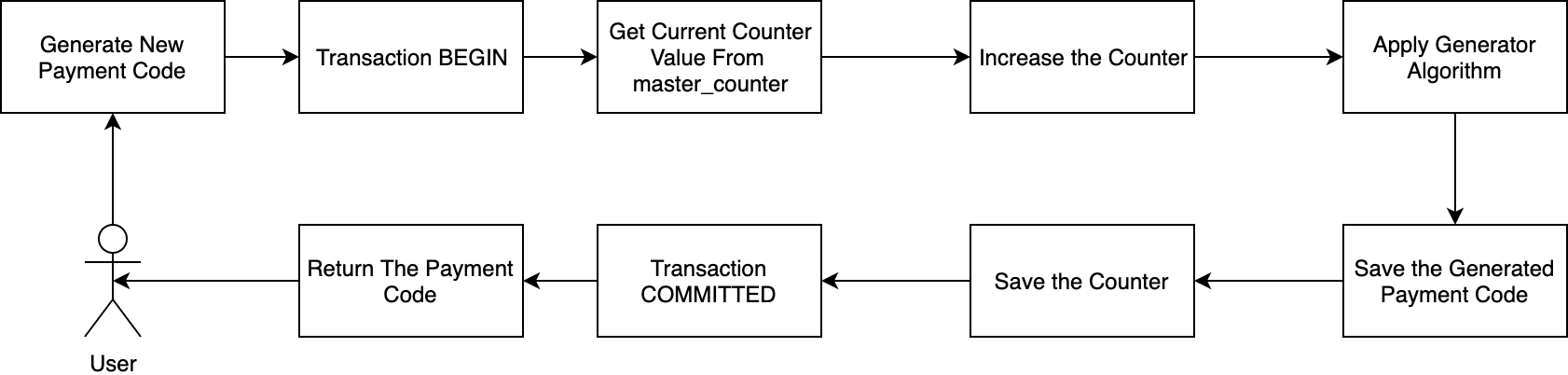
Flow the Generating Payment Code
- When the user requests a new payment code, we will get its current counter value.
- Then we increase the counter value by 1 and apply the algorithm. Or simply just hash the counter value to be a random character.
- After the new counter value hashed, we then store the hashed value to
payment_codetable. With unique constraint. - Then we update the counter value based on user id again to
master_counter. - And finally, we return the hashed counter value to the user, which is a payment code that will be used by our user.
More and less the whole logic is like that. Actually there’s a lot of algorithms used here, but to simplify, all the process is more like I write above.
Problems Started
Initially, if written in SQL my query is more look like this.
BEGIN;
SELECT counter FROM master_counter;
// Do Addition to counter in application
// Apply Generator Logic in Application
INSERT INTO payment_code(payment_code) VALUES(generated_value_with_counter);
UPDATE master_counter SET counter=<new_value_from_application>;
COMMIT;
And since I’m using Golang for the application. In Golang, we can do a transaction with easy. This is the pseudo-code of how I do it in Golang.
tx,_:=db.Begin() // Begin the transaction
counter, err:= SelectCounter(tx) // Select the `counter`
if err != nil {
tx.Rollback() // Rollback if any error occured
}
counter++ // increase the counter
generatedCode:=ApplyAlgorithm(counter) // apply the algorithm
err:= SaveGeneratedCode(tx, generatedCode) // save the payment_code
if err != nil {
tx.Rollback() // Rollback if any error occured
}
err:=UpdateCounter(tx, counter) // update the counter to DB
if err != nil {
tx.Rollback() // Rollback if any error occured
}
tx.Commit() // commit the transaction
All this function is working perfectly when I try with a single request. There’s no error or bug happening. But, when I try to do load testing. Just with only 2 concurrent users. I got these errors a lot.
pq: duplicate key value violates unique constraint \"my_unique_payment_code_index\"
It says, duplication error on payment_code. This is happening because the generated payment_code has to be unique.
Well, as an application it’s not wrong anyway. Because we return an error. But, from the business point of view, how could it return the duplication error, when the user is requesting a “new” payment_code that never used yet?
My first assumption is, if there’s a duplication, it means, that there’s a race condition here. The race condition happened when I’m doing an update and read on the counter value. And because the counter will be hashed for the payment code, and the payment code must be unique, but because of the race condition, there’s a condition that the application reading the same value of the counter and that’s causing duplicate key violations.
In simple, the error occurs because we have met with a race condition where the counters are not updated when concurrent requests come in, causing duplication to occur when we attempt to create new payment codes in parallel requests.
First Attempt! – Using Isolation Level
Knowing this, I started to get confused. Because I’ve used the transaction here. Spending my whole day to search and learn about the transaction, bring me to these articles
- https://pgdash.io/blog/postgres-transactions.html
- http://shiroyasha.io/transaction-isolation-levels-in-postgresql.html
- https://blog.gojekengineering.com/on-concurrency-control-in-databases-1e34c95d396e
I realized that there’s also an isolation level on the transaction. Reading all those articles made me remember my old days in college life. I remember I’ve learned this, but I never found a case when I need to really understand about this.
From those articles, I can conclude that my isolation level on my transaction is not enough to lock the concurrent read-write-update processes in my database. So then I add the isolation level to my application.
_, err := tx.ExecContext(ctx, "SET TRANSACTION ISOLATION LEVEL REPEATABLE READ")
if err != nil {
return
}
And try to re-run my application again. And now the error is different.
pq: could not serialize access due to concurrent update
It’s succeeding to avoid the duplication error. But, it’s totally blocked concurrent request. So it’s no different from having 1 concurrent request to a lot concurrent request.
Since we want this system would be able to handle requests concurrently. So then I’m asking a lot of my friends, even my friend that not work in my company. And even many Senior DBA from other companies. I’m asking for suggestions and advice from them.
And thanks to them, I realized, what I need is a row-level locking. Since I only need to read and update the counter value, so what I need is only on the row-level locking mechanism.
And after understanding my condition, it’s brought me to my second try, using row-level locking.
Second Attempt! - Using SELECT FOR UPDATE
Since I just want on row-level locking, I don’t need a strict isolation level. Because isolation level is for table scope.
So my second try is:
- Isolation level:
READ COMMITTED(Postgres default isolation level) - Row-level locking:
SELECT ... FOR UPDATE
The change is only adding the FOR UDPATE in my select query for my counter value. Compare to my previous SQL query, this is my new query now.
BEGIN;
SELECT counter FROM master_counter FOR UDPATE; // notice this
// Do Addition to counter in application
// Apply Generator Logic in Application
INSERT INTO payment_code(payment_code) VALUES(generated_value_with_counter);
UPDATE master_counter SET counter=<new_value_from_application>;
COMMIT;
So I only add the FOR UPDATE and it’s solved my problem.
Actually I don’t know yet if this is the right solution. But for now, at least it solves our current problem.
Actually, there’s a lot of things that need to understand about SELECT ... FOR UPDATE like explained in this article http://shiroyasha.io/selecting-for-share-and-update-in-postgresql.html
But, with only a simple SELECT ... FOR UDPATE already solve our issue. Maybe later there’s will be a new issue, we leave that for future problems 😎