
How To Do Pagination in Postgres with Golang in 4 Common Ways
A few examples of pagination on Postgres, with Benchmark, written on Golang

Hi again everyone, it’s been a long time I haven’t published any article. There’s a lot of things happen, like from the pandemic and much more stuff. This pandemic affecting me mentally personally, like this self-quarantine is really exhausting and stressing me enough. I wish this Covid-19 pandemic will be ended before Christmas this year. 😭
On this rare occasion, after fighting with the boredom and laziness, I found a spirit to finish this article. Start from me when building our new application in my current job, I’m curious about a few things, and in this part, it’s about pagination. Like how to handle pagination in a better way based on my understanding LOL. *My proposed idea might not be the best, so if you guys have a better way, a vast experience than me, put your comments below yaa!!
TBH, I never care more details about this in my previous job because we all have the same perspective, and we only like to have 10 engineers in my previous company, so we can have the same perspective. But now I care about this, since we have a lot of engineers in my current job, and everyone has a different perspective.
So, I’m just curious, what’s the better way in building pagination on Postgres on top of the application, with my case I’m using Golang for the application.
Actually, there are 2 famous styles of pagination:
- Cursor based pagination
- Offset based pagination
In this article I’ll only cover those 2 style paginations in 4 different common ways that Backend engineer usually does, or at least, what I know so far since I know how to code.
- Do pagination with page number, pretty common, the user only sends the page number, and we handle it internally, I use offset in the database level.
- Do pagination with offset and limit, pretty common since the RDBMS features. The user will directly send the offset number from query param.
- Do pagination with a simple query with an auto incremental ID as the PK, quite common for auto incremental ID in the database. Which is the ID is treated as the cursor.
- Do pagination with UUID as the PK combined with the created timestamp, also known as the seek-pagination method, or keyset pagination method. And the combined key will be hashed into a cursor string.
So what I’m gonna do here are, I’ll create those 4 pagination implementations, and do a small benchmark from code, I’ll using Golang Benchmark. The goal of this article is just to satisfy my curiosity LOL. I know I can read people’s articles, but I want to do it with my own version.
TL;DR
- All the code used here already pushed to my Github repository, github.com/bxcodec/go-postgres-pagination-example
- Conclusions can be seen at the bottom of this article
Pagination On REST API
To give you some context, *in case you don’t know what is pagination used for. Pagination is used to paginate your response, LOL. Well, I don’t know how to rephrase it better.
I’ll create an example, let’s say I have this endpoint, in REST API.
GET /payments
And this endpoint will fetch all payments from the API. As we know, in bigger scale application that has tons of data set, these payments may have thousands or millions of data rows. And as a user, I want to fetch my payments list.
From a database perspective, querying all the records will takes time a lot. I can imagine how long it will be if we have a million records and fetch all the data. So, in that case, people introduce what they called pagination. It works like pages on the books, that each page contains a bunch of words.
But for this endpoint, each page will contain a list of payment details, so we can still fetch the payment faster but maybe it will truncated into multiple pages until we can fetch all the payment records.
GET /payments?page=1 // to fetch payments in page 1
GET /payments?page=2 // to fetch payments in page 2
GET /payments?page=3 // to fetch payments in page 3
... etc
You may have seen this style in any endpoint, or maybe something like this as well.
GET /payments?limit=10 // initial request for fetch payment
GET /payments?limit=10&cursor=randomCursorString // with cursor
GET /payments?limit=10&cursor=newrandomCursorString // for next page
GET /payments?limit=10&cursor=anotherNewrandomCursorString
... etc
And many more, this is what we called pagination. We truncate our list of data into a few segments and send it to the client, so we still maintain the performance of the application and the client won’t lose track when fetching our data.
1. Pagination with Page Number
GET /payments?page=1 // to fetch payments in page 1
GET /payments?page=2 // to fetch payments in page 2
GET /payments?page=3 // to fetch payments in page 3
... etc
Have you seen pagination like those above? TBH, I never have seen any pagination like those, not in public API if I remember correctly. But, I’ve ever created pagination with that’s style, around 4 years ago, on my first job-test after graduated.
So the logic quite complicated in the backend, but it will simplify from the user experience,
- First I’ll set the default limit, let’s say 10. Per page is 10 items.
- And each page number will be multiplied to the default limit
- Then I’ll use it as the offset to the database.
- And, the user can fetch the items based on the requested page number.
So then, I try to build again a simple application for this kind of method. With 100K rows of data, I try to benchmark it.
Benchmark Result
Benchmark Result using Go for PageNumber pagination
The drawback of this pagination method is
- Performance-wise, it’s not recommended. The bigger the data set, the bigger the resource consumption.
But the benefit of using this method, the user feels like opening a book, they will just need to pass the page number.
2. Pagination with Offset and Limit
Pagination with offset and limit is quite common to engineers. This comes because of the feature of RDBMS that supports offset and limit for querying.
From the application level, there’s no extra logic, just passing the offset and limit to the database, and let the database do the pagination.
How is usually looks like,
GET /payments?limit=10 // initial
GET /payments?limit=10&offset=10 //fetch the next 10 items
GET /payments?limit=10&offset=20 //fetch the next 10 items again
... etc
From the client-side, they only need to add the offset params, and the API will return the items based on the given offset.
And from database level, which is RDBMS, it will look like this below,
SELECT
*
FROM
payments
ORDER BY created_time
LIMIT 10
OFFSET 20;
Benchmark Result
Benchmark Result using Go for LimitOffset pagination
The drawback of this pagination method
- Performance-wise, it’s not recommended. The bigger the data set, the bigger the resource consumption.
The benefits of this pagination method
- Very easy to implement, no need to do complex logic things in the server
3. Pagination with Auto Incremental PK of the ID
This pagination method was also pretty common. We set our table to be auto increment, and use that as the page identifier/cursor.
How it’s used in REST
GET /payments?limit=10
GET /payments?limit=10&cursor=last_id_from_previous_fetch
GET /payments?limit=10&cursor=last_id_from_previous_fetch
... etc
How it looks like in database query level
SELECT
*
FROM
payments
WHERE
Id > 10
LIMIT 20
Or for descending
SELECT
*
FROM
payments
WHERE
Id < 100
ORDER BY Id DESC
LIMIT 20
Benchmark Result
Benchmark Result using Go for AutoIncrement pagination
The drawback of this pagination method
- The only drawback of this pagination method is, when using the auto-increment id, it will be problematic in the world of microservice and distributed system. Like id with 20 can exist in Service Payment and Service User. It’s unique in the same application context. It will different if each ID using UUID, it’s “practically unique” (means, there’s a very small possibility of duplicate generated UUID). So some people trying to use UUID instead as the PK. Read more details about UUID and auto-increment keys here
The benefits of this pagination method
- Easy to implement, no need to do complex logic things in the server.
- The best way to do pagination that I know so far from performance-wise, since it’s using autoincrement ID.
4. Pagination with UUID Combined with Created Timestamp
I’m not sure this is pretty common, but I see that a few articles do this kind of pagination. The context is, the table not using auto incremental id, but it’s using the UUID instead. But then people wondering how to do pagination, adding a new column with auto incremental number is a wasting resource. So for myself, what I do is, using the created timestamp of my rows, and combine it with the PK which is the UUID.
This is the database schema
payment.sql schema with UUID and timestamp
And for the faster queries, I make an index with multiple tables which is the PK and the created timestamp, as you can see from the above schema, I made an index named idx_payment_pagination.
So the logic is,
- I’ll use the UUID which is my primary key, and combine it with create timestamp
- Combine those two into a string, then I encode it to base64 string
- And return that encoded string as a cursor for the next page, so the user can use it to fetch the next page of their request.
Example of how I made the cursor on application level
And this is how it looks like in the REST endpoint.
GET /payments?limit=10
GET /payments?limit=10&cursor=base64_string_from_previous_result
GET /payments?limit=10&cursor=base64_string_from_previous_result
... etc
But in the database, the query will look like this,
SELECT *
FROM payments
WHERE created_time <= '2020-05-16 03:15:06' -- created timestamp
AND id < '2a1aa856-ad26-4760-9bd9-b2fe1c1ca5aa' -- this is UUID
ORDER BY created_time DESC
LIMIT 2
Benchmark Result
Benchmark Result using Go for Keyset pagination
The drawback of this pagination method
- The performance may not be the best like using the autoincrement id. But it’s consistent even we will have millions of data
- Quite tricky and advanced, we need to understand the index, because if we didn’t add an index, this query will really take time on a big dataset. And also we need to careful when handling timestamps. Even I, still facing some issues when querying the timestamp when doing this.
The benefits of this pagination method
- The ID is UUID, so it’s practically globally unique across microservice in the organizations.
- The performance is consistent from the beginning until querying the last page of the data
Conclusions
Alright, after doing all the benchmark, I’ve come with some conclusions.
1. Performances: Faster to Slower
From the benchmark results (using the Golang benchmark tool), the faster one is using the autoincrement PK. See the chart below, the smaller the faster, the chart for the average-time needed for each operation in nanoseconds. This chart is might not be a good representation, it’s should be better if I make it in 95th, 97th, etc percentile, but I got this value from the benchmark result. So I assume this is already good enough for the representation.
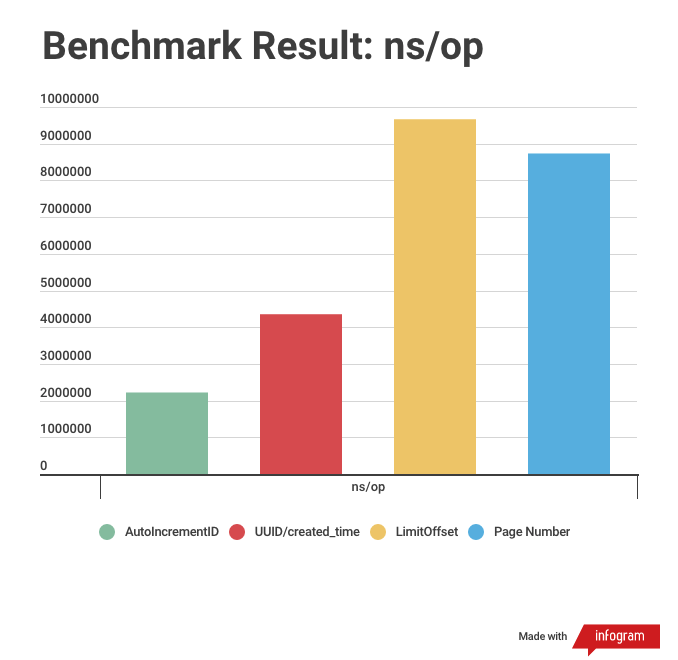
Pagination with autoincrement ID is the faster, followed by UUID/created time, and PageNumber and LimitOffset. And this is only with 100K rows of data. And it will grow bigger as the data grow as well. So with only 100K data, even it still under 1 second, but the differences already quite high when using autoincrement compared to limit offset.
2. Development: Faster to Slower
Implementation difficulties from easy to hard
- Using Offset, because we just only passing the offset and limit directly to the database.
- Using PageNumber, this is opinionated, some people may have different logic, but for my case I put this in the top two.
- Using autoincrement ID
- Using UUID with created time
Code artifacts
For the code, I’ve pushed it to my GitHub repository, can be found here, https://github.com/bxcodec/go-postgres-pagination-example
The issues that I face when doing this
When doing all of these things, obviously I face some issues, but I’ve resolved it, and I also learn about this. I’ve written the things that I learned here, as well in this article: TIL: Becareful on Postgres Query, for Less than Or Equal on Timestamp
Author Suggestion
As a software engineer, and as the author of this article, I recommend to use autoincrement ID when doing pagination, but if your system or you don’t want to use autoincrement ID as the PK, you may consider of using keyset pagination, with my case using UUID + created_time timestamp.
Reference
- Tons of Stackoverflow answer, I forgot which one, but all answers that related to pagination with Postgres.
- Faster SQL Pagination with jOOQ Using the Seek Method
- REST API Design: Filtering, Sorting, and Pagination
Originally posted at: https://medium.com/easyread/how-to-do-pagination-in-postgres-with-golang-in-4-common-ways-12365b9fb528